Abrindo Arquivos de Texto#
Neste curso de mineração de textos usaremos como material principal de trabalho, os verbetes do Dicionário Histórico e Biográfico do Brasil – DHBB. Estes verbetes stão disponíveis para Download público.
Neste capítulo vamos aprender a interagir com os verbetes no disco e extrair informações simples a partir dos mesmos.
Vamos começar importando alguma bibliotecas que nos serão úteis nesta tarefa:
Show code cell source
import warnings
warnings.filterwarnings('ignore')
import os
import glob
print("alô turma!")
alô turma!
Assumindo que os dados do DHBB já foram baixados para um diretório local, podemos começar inspecionando o diretório e listando o seu conteúdo.
# caminho = "F:/dhbb-master/text/*.text"
caminho = "../dhbb/text/*.text"
arquivos = glob.glob(caminho)
len(arquivos)
7838
Temos 7838 verbetes neste diretório. Vamos agora ver como abrir um destes verbetes e inspecionar o seu conteúdo:
arquivos[0]
'../dhbb/text/4736.text'
Para abrir um arquivo utilizamos um bloco with.
with open(arquivos[0],'r', encoding='utf8') as arquivo_aberto:
verbete = arquivo_aberto.read()
print(verbete)
---
title: RUBIM, Floriano
natureza: biográfico
sexo: m
cargos:
- militar
- dep. fed. ES 1955-1959
- dep. fed. ES 1963-1971
---
«Floriano Lopes Rubim» nasceu em Alegre (ES) no dia 18 de janeiro de
1912, filho de Francisco Lopes Rubim, funcionário público, e de Maria
Sílvia Lousada Rubim.
Bacharel em ciências jurídicas e sociais pela Faculdade de Direito da
Universidade do Espírito Santo, formou-se também na Escola de Educação
Física do Rio de Janeiro, então Distrito Federal, em 1941. Nesse mesmo
ano ingressou na Força Policial do Espírito Santo, onde faria carreira.
Participou da campanha militar brasileira na Itália durante a Segunda
Guerra Mundial (1939-1945), retornando ao Brasil em 1945, ao término do
conflito.
Em 1946 assumiu a direção da Penitenciária do Estado do Espírito Santo,
que ocupou até o ano seguinte. Em 1948 passou a ajudante-de-ordens na
Casa Militar do governador do Espírito Santo, Carlos Lindenberg
(1947-1951), função que exerceu até 1949. Em outubro de 1950 elegeu-se
deputado estadual pelo Espírito Santo, na legenda do Partido Trabalhista
Brasileiro (PTB). Para assumir o mandato, foi reformado na Força
Policial do estado no posto de coronel, ocupando a sua cadeira no
Legislativo em fevereiro de 1951. Nessa legislatura integrou as
comissões de Educação e Cultura e de Justiça da Assembléia capixaba.
Em outubro de 1954 elegeu-se deputado federal por seu estado, agora com
o apoio da Coligação Democrática formada pelo PTB e pelos partidos
Republicano (PR), de Representação Popular (PRP) e Social Progressista
(PSP). Encerrou o mandato estadual em janeiro de 1955, assumindo no mês
seguinte sua cadeira na Câmara Federal. Ocupou-a, no entanto, apenas de
2 a 9 de fevereiro, quando se licenciou para assumir a Secretaria de
Viação e Obras Públicas do Espírito Santo no governo de Francisco
Lacerda de Aguiar (1955-1959). Em abril reassumiu o mandato parlamentar
e, até o fim da legislatura, foi vice-presidente da Comissão de
Segurança Nacional da Câmara. Em maio de 1957, tornou-se vice-líder do
PTB. Em outubro de 1958 tentou a reeleição, na mesma legenda, mas obteve
apenas uma suplência. Concluiu o mandato em janeiro de 1959.
Em 1960, participou da campanha de Jânio Quadros para a presidência da
República, filiando-se ao Partido Democrata Cristão (PDC). No entanto,
no dia seguinte ao pleito realizado em outubro e vencido por Jânio,
desligou-se do PDC, filiando-se ao Partido Trabalhista Nacional (PTN).
Em outubro de 1962 voltou a se eleger deputado federal com o apoio da
coligação formada pelo PTN e o Partido Social Democrático (PSD). Assumiu
o mandato em fevereiro de 1963, tornando-se vice-líder do partido na
Câmara em junho do ano seguinte.
Com a edição do Ato Institucional nº 2 (AI-2), em 27 de outubro de 1965,
extinguindo os partidos políticos, e com a posterior implantação do
bipartidarismo, filiou-se à Aliança Renovadora Nacional (Arena), partido
de apoio ao regime militar instalado no país após a deposição do
presidente João Goulart em 31 de março de 1964.
Em novembro de 1966 reelegeu-se deputado federal pelo Espírito Santo, já
na legenda da Arena, exercendo o mandato de fevereiro de 1967 a janeiro
de 1971.
Fundou a Imexferral Ltda., empresa de sua propriedade.
Faleceu no dia 4 de maio de 1997.
Uma outra maneira de abrir um arquivo, seria como se segue, mas teríamos que usar uma linha de código a mais, para fechar o arquivo, que podemos economizar, lendo o arquivo dentro de um bloco with como fizemos anteriormente.
arquivo_aberto = open(arquivos[0], 'r', encoding='utf8')
verbete = arquivo_aberto.read()
arquivo_aberto.close()
A variável verbete que criamos na célula anterior é uma variável do tipo string, que é a otipo usado pelo Python para representar um bloco de texto. Podemos manipular o texto dentro de uma string de diversas maneiras:
type(verbete)
str
print(verbete.split('---')[1])
title: RUBIM, Floriano
natureza: biográfico
sexo: m
cargos:
- militar
- dep. fed. ES 1955-1959
- dep. fed. ES 1963-1971
Tipos de dados em Python, também conhecidos como objetos, possuem métodos. O método split do tipo string segmenta uma string nas posicões em que ocorram uma sequência específica de caracteres, retornando um outro tipo de dado, denominado lista.
type(verbete.split('---'))
list
Listas são sequências de objetos de quaisquer tipos que também apresentam seu conjunto de métodos. Para descobrir os métodos de qualquer objeto, basta colocar um ponto após o nome da variável e pressionar a tecla <tab>. Listas são delimitadas por colchetes: [] (lista vazia). Abaixo vamos dividir o verbete em uma lista de strings.
l = verbete.split('---')
l
['',
'\ntitle: RUBIM, Floriano\nnatureza: biográfico\nsexo: m\ncargos: \n - militar\n - dep. fed. ES 1955-1959\n - dep. fed. ES 1963-1971\n',
'\n\n«Floriano Lopes Rubim» nasceu em Alegre (ES) no dia 18 de janeiro de\n1912, filho de Francisco Lopes Rubim, funcionário público, e de Maria\nSílvia Lousada Rubim.\n\nBacharel em ciências jurídicas e sociais pela Faculdade de Direito da\nUniversidade do Espírito Santo, formou-se também na Escola de Educação\nFísica do Rio de Janeiro, então Distrito Federal, em 1941. Nesse mesmo\nano ingressou na Força Policial do Espírito Santo, onde faria carreira.\nParticipou da campanha militar brasileira na Itália durante a Segunda\nGuerra Mundial (1939-1945), retornando ao Brasil em 1945, ao término do\nconflito.\n\nEm 1946 assumiu a direção da Penitenciária do Estado do Espírito Santo,\nque ocupou até o ano seguinte. Em 1948 passou a ajudante-de-ordens na\nCasa Militar do governador do Espírito Santo, Carlos Lindenberg\n(1947-1951), função que exerceu até 1949. Em outubro de 1950 elegeu-se\ndeputado estadual pelo Espírito Santo, na legenda do Partido Trabalhista\nBrasileiro (PTB). Para assumir o mandato, foi reformado na Força\nPolicial do estado no posto de coronel, ocupando a sua cadeira no\nLegislativo em fevereiro de 1951. Nessa legislatura integrou as\ncomissões de Educação e Cultura e de Justiça da Assembléia capixaba.\n\nEm outubro de 1954 elegeu-se deputado federal por seu estado, agora com\no apoio da Coligação Democrática formada pelo PTB e pelos partidos\nRepublicano (PR), de Representação Popular (PRP) e Social Progressista\n(PSP). Encerrou o mandato estadual em janeiro de 1955, assumindo no mês\nseguinte sua cadeira na Câmara Federal. Ocupou-a, no entanto, apenas de\n2 a 9 de fevereiro, quando se licenciou para assumir a Secretaria de\nViação e Obras Públicas do Espírito Santo no governo de Francisco\nLacerda de Aguiar (1955-1959). Em abril reassumiu o mandato parlamentar\ne, até o fim da legislatura, foi vice-presidente da Comissão de\nSegurança Nacional da Câmara. Em maio de 1957, tornou-se vice-líder do\nPTB. Em outubro de 1958 tentou a reeleição, na mesma legenda, mas obteve\napenas uma suplência. Concluiu o mandato em janeiro de 1959.\n\nEm 1960, participou da campanha de Jânio Quadros para a presidência da\nRepública, filiando-se ao Partido Democrata Cristão (PDC). No entanto,\nno dia seguinte ao pleito realizado em outubro e vencido por Jânio,\ndesligou-se do PDC, filiando-se ao Partido Trabalhista Nacional (PTN).\nEm outubro de 1962 voltou a se eleger deputado federal com o apoio da\ncoligação formada pelo PTN e o Partido Social Democrático (PSD). Assumiu\no mandato em fevereiro de 1963, tornando-se vice-líder do partido na\nCâmara em junho do ano seguinte.\n\nCom a edição do Ato Institucional nº 2 (AI-2), em 27 de outubro de 1965,\nextinguindo os partidos políticos, e com a posterior implantação do\nbipartidarismo, filiou-se à Aliança Renovadora Nacional (Arena), partido\nde apoio ao regime militar instalado no país após a deposição do\npresidente João Goulart em 31 de março de 1964.\n\nEm novembro de 1966 reelegeu-se deputado federal pelo Espírito Santo, já\nna legenda da Arena, exercendo o mandato de fevereiro de 1967 a janeiro\nde 1971.\n\nFundou a Imexferral Ltda., empresa de sua propriedade.\n\nFaleceu no dia 4 de maio de 1997.\n\n']
Note que nas strings acima existem várias ocorrências da sequencia de caracteres '\n'. Esta sequência identifica quebra de linhas. Podemos então utilizá-la para dividir o cabeçalho do verbete em uma lista de linhas:
cabeçalho = verbete.split('---')[1]
cabeçalho.splitlines()
['',
'title: RUBIM, Floriano',
'natureza: biográfico',
'sexo: m',
'cargos: ',
' - militar',
' - dep. fed. ES 1955-1959',
' - dep. fed. ES 1963-1971']
Elementos de uma lista podem ser acessado por sua posição na sequência, por exemplo para acessar a 3ª string da lista:
print(l[2])
«Floriano Lopes Rubim» nasceu em Alegre (ES) no dia 18 de janeiro de
1912, filho de Francisco Lopes Rubim, funcionário público, e de Maria
Sílvia Lousada Rubim.
Bacharel em ciências jurídicas e sociais pela Faculdade de Direito da
Universidade do Espírito Santo, formou-se também na Escola de Educação
Física do Rio de Janeiro, então Distrito Federal, em 1941. Nesse mesmo
ano ingressou na Força Policial do Espírito Santo, onde faria carreira.
Participou da campanha militar brasileira na Itália durante a Segunda
Guerra Mundial (1939-1945), retornando ao Brasil em 1945, ao término do
conflito.
Em 1946 assumiu a direção da Penitenciária do Estado do Espírito Santo,
que ocupou até o ano seguinte. Em 1948 passou a ajudante-de-ordens na
Casa Militar do governador do Espírito Santo, Carlos Lindenberg
(1947-1951), função que exerceu até 1949. Em outubro de 1950 elegeu-se
deputado estadual pelo Espírito Santo, na legenda do Partido Trabalhista
Brasileiro (PTB). Para assumir o mandato, foi reformado na Força
Policial do estado no posto de coronel, ocupando a sua cadeira no
Legislativo em fevereiro de 1951. Nessa legislatura integrou as
comissões de Educação e Cultura e de Justiça da Assembléia capixaba.
Em outubro de 1954 elegeu-se deputado federal por seu estado, agora com
o apoio da Coligação Democrática formada pelo PTB e pelos partidos
Republicano (PR), de Representação Popular (PRP) e Social Progressista
(PSP). Encerrou o mandato estadual em janeiro de 1955, assumindo no mês
seguinte sua cadeira na Câmara Federal. Ocupou-a, no entanto, apenas de
2 a 9 de fevereiro, quando se licenciou para assumir a Secretaria de
Viação e Obras Públicas do Espírito Santo no governo de Francisco
Lacerda de Aguiar (1955-1959). Em abril reassumiu o mandato parlamentar
e, até o fim da legislatura, foi vice-presidente da Comissão de
Segurança Nacional da Câmara. Em maio de 1957, tornou-se vice-líder do
PTB. Em outubro de 1958 tentou a reeleição, na mesma legenda, mas obteve
apenas uma suplência. Concluiu o mandato em janeiro de 1959.
Em 1960, participou da campanha de Jânio Quadros para a presidência da
República, filiando-se ao Partido Democrata Cristão (PDC). No entanto,
no dia seguinte ao pleito realizado em outubro e vencido por Jânio,
desligou-se do PDC, filiando-se ao Partido Trabalhista Nacional (PTN).
Em outubro de 1962 voltou a se eleger deputado federal com o apoio da
coligação formada pelo PTN e o Partido Social Democrático (PSD). Assumiu
o mandato em fevereiro de 1963, tornando-se vice-líder do partido na
Câmara em junho do ano seguinte.
Com a edição do Ato Institucional nº 2 (AI-2), em 27 de outubro de 1965,
extinguindo os partidos políticos, e com a posterior implantação do
bipartidarismo, filiou-se à Aliança Renovadora Nacional (Arena), partido
de apoio ao regime militar instalado no país após a deposição do
presidente João Goulart em 31 de março de 1964.
Em novembro de 1966 reelegeu-se deputado federal pelo Espírito Santo, já
na legenda da Arena, exercendo o mandato de fevereiro de 1967 a janeiro
de 1971.
Fundou a Imexferral Ltda., empresa de sua propriedade.
Faleceu no dia 4 de maio de 1997.
Muitas vezes, as atrings podem vir acompanhadas de um ou mais espaços no ínicio ou no fim. Para removê-los podemos usar o método strip como exemplificado abaixo. Caso queiramos remover apenas os espaços no início ou no fim, podemos usar lstrip ou rstrip, respectivamente.
" gjsldfkgj ".strip()
'gjsldfkgj'
Um outro tipo de estrutura de dados fundamental no Python, é chamado um dicionário, e é denotado por um conjunto de pares de (chave: valor). Abaixo vamos construir um dicionário com os campos de um verbete.
campos = {l.split(':')[0].strip() :l.split(':')[1].strip() for l in cabeçalho.split('\n') if l and ':' in l}
campos
{'title': 'RUBIM, Floriano',
'natureza': 'biográfico',
'sexo': 'm',
'cargos': ''}
No exemplo acima usamos um laço for para percorrer repetidamente o campos do cabeçalho e inseri-los um-a-um no dicionário, em apenas uma linha de código. esta maneira de prencher o dicionário é chamada de “dict comprehension”. Para entendermos melhor como funciona um laço for, e exatament a sequencia de operações realizada acima, vamos escrever “por extenso” o código acima.
campos = {}
for linha in cabeçalho.split('\n'):
if linha and ':' in linha:
chave, valor = linha.split(':')
campos[chave.strip()] = valor.strip()
campos
{'title': 'RUBIM, Floriano',
'natureza': 'biográfico',
'sexo': 'm',
'cargos': ''}
Exercícios#
Construa para 5 verbetes, um dicionário com o seguinte conteúdo: {"nome-do-cargo":"período"} para todos os cargos de cada verbetado.
def pega_cabeçalho(caminho, natureza):
with open(caminho, 'r', encoding='utf8') as verb:
cabeçalho = verb.read().split('---')[1]
if natureza in cabeçalho:
return cabeçalho
else:
return
respostas = []
for verbete in arquivos[10:18]:
resposta = {}
cabeçalho = pega_cabeçalho(verbete, 'biográfico')
if cabeçalho is None:
continue
cargos = cabeçalho.split('cargos:')[1]
lista_de_cargos = [cargo.strip('- ') for cargo in cargos.splitlines() if cargo.strip('- ') != ""]
for cargo in lista_de_cargos:
partes = cargo.split()
if len(partes) > 1:
per = partes[-1]
nome = ' '.join(partes[:-1])
else:
nome = partes[0]
per = "NA"
resposta[nome] = per
respostas.append(resposta)
# print(cargos)
print(resposta)
print(sum([1 for r in respostas if 'autor:' in r]))
{'empresário': 'NA', 'autor:': 'NA', 'Maria Ester Lopes': 'Moreira'}
{'dep. fed. TO': '2007'}
{'militar': 'NA', 'rev.': '1930', 'dep. fed. MG': '1959-1979'}
{'magistrado': 'NA', 'min. STF': '2003-2012', 'autor:': 'NA', 'Eduardo': 'Junqueira', 'Raimundo': 'Hélio'}
{'magistrada': 'NA', 'min. STF': '2006', 'pres. STF': '2016', 'autor:': 'NA', 'Eduardo': 'Junqueira', 'Raimundo': 'Hélio', 'Regina Hippolito': '(atualização)'}
{'dep. fed. PR': '1999'}
{'magistrado': 'NA', 'min. STF': '2006', 'autor:': 'NA', 'Eduardo': 'Junqueira'}
{'dep. fed. SC': '1971-1979'}
4
Na célula acima contruímos uma variável de tipo Dicionário, que é basicamente um conjunto de pares, delimitado por {}. Estes pares são chamados pares chave: valor, como dissemos anteriormente.
Modifique o código acima para criar outro dicionário com a seguinte estrutura:
{
"nome": ["nome do verbetado", "nome do verbetado", ...],
"cargo":[cargo 1, cargo2, ...],
"início": [1987,1987, ...],
"fim": [1988, 1991, ...]
}
import re
regex = re.compile('([0-9-]{4,5})')
cargo = " - emb. Itália no Brasil 1932-1937"
re.findall(regex,cargo)
['1932-', '1937']
import re
regex = re.compile('([0-9-]{4,5})')
resposta = {"nome": [], "cargo":[], "sexo":[], "inicio":[], "fim":[]}
for verbete in arquivos:
cabeçalho = pega_cabeçalho(verbete, 'biográfico')
if cabeçalho is None:
continue
cabeçalho = cabeçalho.split('autor:')[0]
linhas = cabeçalho.splitlines()
cargos = cabeçalho.split('cargos:')[1]
lista_de_cargos = [cargo.strip('- ') for cargo in cargos.splitlines() if cargo.strip('- ') != ""]
for cargo in lista_de_cargos:
resposta['nome'].append([linha.split(':')[1].strip() for linha in linhas if linha.startswith('title:')][0])
try:
resposta['sexo'].append([linha.split(':')[1].strip() for linha in linhas if linha.startswith('sexo:')][0])
except IndexError:
resposta['sexo'].append('NA')
print("sexo: ")
print(cabeçalho)
m = re.findall(regex,cargo)
if m:
corte = cargo.index(m[0])
partes = (cargo[:corte], cargo[corte:])
else:
partes = [cargo]
if len(partes) > 1:
per = m
nome = partes[0]
try:
resposta['inicio'].append(int(m[0].strip('-')))
except ValueError:
resposta['inicio'].append('NA')
#print("inicio:", per, per.split('-')[0])
print(cabeçalho)
if len(per)>1:
try:
resposta['fim'].append(int(m[1]))
except ValueError:
resposta['fim'].append("NA")
print("fim:", per, m[1])
else:
resposta['fim'].append("NA")
else:
nome = partes[0]
resposta['inicio'].append("NA")
resposta['fim'].append("NA")
resposta['cargo'].append(nome.strip())
# print(cargos)
# print(resposta)
#print(sum([1 for r in resposta if 'autor:' in r]))
print(pega_cabeçalho(arquivos[3], 'biográfico'))
title: KRÜGER, Nivaldo
natureza: biográfico
sexo: m
cargos:
- dep. fed. PR 1979-1983
- sen. PR 2002-2003
Abrindo um grande número de documentos texto#
Como vimos acima existem 7687 verbetes à nossa disposição no disco, mas não podemos abrir todos ao mesmo tempo pois, em primeiro lugar podem não caber na memória, em segundo lugar raramente precisaremos inpecioná-los todos ao mesmo tempo. O mais comum é analisá-los em sequência. Vamos inspecionar os primeiros 10:
for a in arquivos[:10]:
with open (a, 'r', encoding='utf8') as f:
verbete = f.readlines()
print('Verbete: ', a.split('.text')[0].split('/')[-1])
print(verbete[1])
Verbete: 4736
title: RUBIM, Floriano
Verbete: 1376
title: COELHO, Inocêncio Mártires
Verbete: 732
title: BOPP, Raul
Verbete: 2669
title: KRÜGER, Nivaldo
Verbete: 6310
title: POLÍTICA DE CLIENTELA
Verbete: 3752
title: NASCIMENTO, César
Verbete: 10928
title: COLA, Camilo
Verbete: 3756
title: NASCIMENTO, Paulo
Verbete: 41
title: ADEODATO, Francisco
Verbete: 11169
title: LIMA, Eliene
arquivos[1]
'../dhbb/text/1376.text'
Acima utilizamos uma estrutura de repetição, denominada “laço for” para abrir sequencialmente os arquivos. É importante notar que a cada volta do laço, o arquivo texo é atribuído à mesma variável, o que significa que nunca há mais do que apenas um verbete na memória. Desta forma poderíamos potencialmente analisar todos os milhares de verbetes ocupando apenas uma quantidade pequena e constante de memória. Outro detalhe do código acima é que, para facilitar a extração do título do verbete, Fizemos a leitura do arquivo com o método readlines que retorna o verbete já divido em uma lista de linhas ao invés de uma string.
Outros recursos do DHBB#
O arquivo do DHBB disponível no Github oferece outros recursos textuais para nos auxiliar em nossa pesquisa, como por exemplos dicionários com identificadores de “Entidades” presentes nos verbetes, como pessoas, organizações, eventos, etc.
with open("../dhbb/dic/pessoa-individuo.txt", 'r', encoding='utf8') as f:
pessoas = f.readlines()
pessoas[:10]
['Aarão Rebelo\n',
'Aarão Steinbruch\n',
'Abalcazar Garcia\n',
'Abdias Do Nascimento\n',
'Abdon Goncalves Nanhay\n',
'Abdon Gonçalves\n',
'Abdon Sena\n',
'Abdon de Mello\n',
'Abdur R. Khan\n',
'Abel Avila dos Santos\n']
with open("../dhbb/dic/pessoa-papel.txt", 'r', encoding='utf8') as f:
profissão = f.readlines()
profissão[:10]
['Advogado\n',
'Advogado Geral da União\n',
'Agente de investimento\n',
'Agente de segurança judiciária\n',
'Alfaiate\n',
'Analista administrativo\n',
'Analista de comércio exterior\n',
'Antiquário\n',
'Arcebispo\n',
'Armador\n']
with open("../dhbb/dic/evento.txt", 'r', encoding='utf8') as f:
evento = f.readlines()
evento[:10]
['A Rusga\n',
'ATENTADO DA TONELEIROS\n',
'ATENTADO DO RIOCENTRO\n',
'Aclamação de Amador Bueno\n',
'Balaiada\n',
'Batalha da Maria Antônia\n',
'Batalha da Venda Grande\n',
'Batalha das Toninhas\n',
'Batalha de Santa Luzia\n',
'COMÍCIO DAS REFORMAS\n']
with open("../dhbb/dic/organizacao.txt", 'r', encoding='utf8') as f:
organização = f.readlines()
organização[:10]
['Abrigo Lar dos Velhos Vicentini\n',
'Academia Alagoana de Letras\n',
'Academia Brasileira de Ciências\n',
'Academia Brasileira de Ciências Econômicas e Administrativas\n',
'Academia Brasileira de Ciências Sociais e Políticas\n',
'Academia Brasileira de Direito Empresarial\n',
'Academia Brasileira de Letras\n',
'Academia Brasileira de Música\n',
'Academia Brasiliense de Letras\n',
'Academia Cultural de Curitiba\n']
with open("../dhbb/dic/formulacao-politica.txt", 'r', encoding='utf8') as f:
politica = f.readlines()
politica[:10]
['anteprojeto Constitucional\n',
'anteprojeto da Carta Magna\n',
'anteprojeto da Comissão Provisória\n',
'anteprojeto da Comissão Provisória de Estudos Constitucionais\n',
'anteprojeto da Comissão de Sistematização\n',
'anteprojeto da Consolidação das Leis do Trabalho\n',
'anteprojeto da Constituição\n',
'anteprojeto da Lei Orgânica da Magistratura\n',
'anteprojeto da Lei de Acidentes no Trabalho\n',
'anteprojeto da Lei de Direitos Autorais\n']
Extraindo Informação Estruturada#
Agora que sabemos como abrir arquivos de texto e ler o seu conteúdo, podemos experimentar a extração de imformações específicas dos verbetes e organizá-la em uma tabela. Para isso vamos lançar mão de uma biblioteca chamada Pandas para organizar em uma estrutura tabular, chamada DataFrame os dados que vamos extrair.
import pandas as pd
# pd.set_option("display.latex.repr", True)
%matplotlib inline
Nós vimos acima que os verbetes contém uma seção inicial delimitada pelos caracteres --- vamos utilizar esta característica do texto para guiar nossa extração de informação. Como você pode perceber, já começamos a reutilizar código que escrevemos anteriormente. Para facilitar o reuso e reduzir a necessidade de escrever múltiplas vezes o mesmo código vamos aprender a organizá-lo melhor. Vamos começar definindo uma função.
def tabula_verbete(n=None):
"""
Carrega todos os verbetes disponíveis, ou os primeiros n.
n: número de verbetes a tabular
"""
if n is None:
n = len(arquivos)
linhas = []
for a in arquivos[:n]:
with open (a, 'r', encoding='utf8') as f:
verbete = f.read()
cabeçalho = verbete.split('---')[1]
campos = {l.split(':')[0].strip() :l.split(':')[1].strip() for l in cabeçalho.split('\n')[:4] if l}
campos['arquivo'] = os.path.split(a)[1]
campos['cargos'] = 'NA' if 'cargos:' not in cabeçalho else cabeçalho.split('cargos:')[1]
campos['corpo'] = verbete.split('---')[2]
linhas.append(campos)
tabela = pd.DataFrame(data = linhas, columns=['arquivo','title', 'natureza', 'sexo', 'cargos', 'corpo'])
return tabela
A função acima inclui a maior parte do código que escrevemos anteriormente, só que encapsulado em uma função que nos permite executar a extração e tabulação do cabeçalho para o numero de verbetes que desejarmos. Podemos ver abaixo que na verdade é muito rápido processar todos os verbetes.
help(tabula_verbete)
Help on function tabula_verbete in module __main__:
tabula_verbete(n=None)
Carrega todos os verbetes disponíveis, ou os primeiros n.
n: número de verbetes a tabular
tab = tabula_verbete()
tab.head()
| arquivo | title | natureza | sexo | cargos | corpo | |
|---|---|---|---|---|---|---|
| 0 | 4736.text | RUBIM, Floriano | biográfico | m | \n - militar\n - dep. fed. ES 1955-1959\n - d... | \n\n«Floriano Lopes Rubim» nasceu em Alegre (E... |
| 1 | 1376.text | COELHO, Inocêncio Mártires | biográfico | m | \n - proc. ger. Rep. 1981-1985\nautor: \n - L... | \n\n«Inocêncio Mártires Coelho» nasceu em Belé... |
| 2 | 732.text | BOPP, Raul | biográfico | m | \n - diplomata\n - emb. Bras. Peru 1962-1963\n | \n\n«Raul Bopp» nasceu em Santa Maria (RS) no ... |
| 3 | 2669.text | KRÜGER, Nivaldo | biográfico | m | \n - dep. fed. PR 1979-1983\n - sen. PR 2002-... | \n\n«Nivaldo Passos Krüger» nasceu em Canoinha... |
| 4 | 6310.text | POLÍTICA DE CLIENTELA | temático | NaN | NA | \n\nExpressão cunhada e conceito desenvolvido ... |
Podemos visualizar uma descrição básica da tabela resultante
tab.describe()
| arquivo | title | natureza | sexo | cargos | corpo | |
|---|---|---|---|---|---|---|
| count | 7838 | 7838 | 7838 | 6865 | 7838 | 7838 |
| unique | 7838 | 7760 | 2 | 2 | 6189 | 7836 |
| top | 2058.text | ALVES, José | biográfico | m | NA | \n\nPartido político que se habilitou junto ao... |
| freq | 1 | 3 | 6865 | 6615 | 973 | 2 |
Por exemplo fica fácil ver que no DHBB predominam biografias de personagens do sexo masculino.
print(tab.sexo.value_counts())
sexo
m 6615
f 250
Name: count, dtype: int64
tab.sexo.hist();
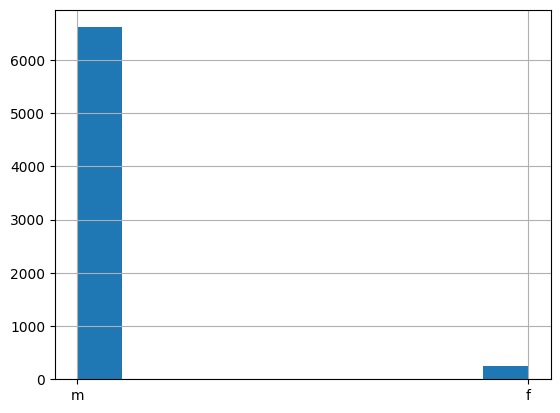
Percebemos também que a natureza predominante dos verbetes é biográfica e que só existem duas naturezas, mas qua a outra?
print(tab.natureza.value_counts())
natureza
biográfico 6865
temático 973
Name: count, dtype: int64
tab2 = pd.DataFrame(resposta)
tab2.inicio = tab2.inicio.replace('NA', pd.NA)
tab2.fim = tab2.fim.replace('NA', pd.NA)
tab2.head()
| nome | cargo | sexo | inicio | fim | |
|---|---|---|---|---|---|
| 0 | RUBIM, Floriano | militar | m | <NA> | <NA> |
| 1 | RUBIM, Floriano | dep. fed. ES | m | 1955 | 1959 |
| 2 | RUBIM, Floriano | dep. fed. ES | m | 1963 | 1971 |
| 3 | COELHO, Inocêncio Mártires | proc. ger. Rep. | m | 1981 | 1985 |
| 4 | BOPP, Raul | diplomata | m | <NA> | <NA> |
for c, v in resposta.items():
print(c, len(v))
nome 15083
cargo 15083
sexo 15083
inicio 15083
fim 15083
tab2.dropna()
| nome | cargo | sexo | inicio | fim | |
|---|---|---|---|---|---|
| 1 | RUBIM, Floriano | dep. fed. ES | m | 1955 | 1959 |
| 2 | RUBIM, Floriano | dep. fed. ES | m | 1963 | 1971 |
| 3 | COELHO, Inocêncio Mártires | proc. ger. Rep. | m | 1981 | 1985 |
| 5 | BOPP, Raul | emb. Bras. Peru | m | 1962 | 1963 |
| 6 | KRÜGER, Nivaldo | dep. fed. PR | m | 1979 | 1983 |
| ... | ... | ... | ... | ... | ... |
| 15075 | MACIEL, Antunes | dep. fed. RS | m | 1924 | 1927 |
| 15078 | MACIEL, Antunes | min. Just. | m | 1932 | 1934 |
| 15079 | FOGAÇA, José | dep. fed. RS | m | 1983 | 1987 |
| 15080 | FOGAÇA, José | const. | m | 1987 | 1988 |
| 15081 | FOGAÇA, José | sen. RS | m | 1987 | 2003 |
9893 rows × 5 columns
tab2[(['dep.' in c for c in tab2.cargo])&(tab2.inicio >1917)&(tab2.inicio<=2015)]
| nome | cargo | sexo | inicio | fim | |
|---|---|---|---|---|---|
| 1 | RUBIM, Floriano | dep. fed. ES | m | 1955 | 1959 |
| 2 | RUBIM, Floriano | dep. fed. ES | m | 1963 | 1971 |
| 6 | KRÜGER, Nivaldo | dep. fed. PR | m | 1979 | 1983 |
| 8 | NASCIMENTO, César | dep. fed. SC | m | 1973 | 1975 |
| 9 | NASCIMENTO, César | dep. fed. SC | m | 1977 | 1980 |
| ... | ... | ... | ... | ... | ... |
| 15071 | CORREIA, Hélio | dep. fed. BA | m | 1983 | 1987 |
| 15073 | MACIEL, Antunes | dep. fed. RS | m | 1921 | 1923 |
| 15075 | MACIEL, Antunes | dep. fed. RS | m | 1924 | 1927 |
| 15076 | MACIEL, Antunes | dep. fed. RS | m | 1930 | <NA> |
| 15079 | FOGAÇA, José | dep. fed. RS | m | 1983 | 1987 |
6469 rows × 5 columns
tab2[(tab2.cargo.isin(['dep. fed. RJ', 'dep. fed. SP']))&(tab2.inicio==1991)]
#tab2.iloc[14825].cargo
| nome | cargo | sexo | inicio | fim | |
|---|---|---|---|---|---|
| 91 | MIGUEL, Sidnei de | dep. fed. RJ | m | 1991 | 1995 |
| 212 | ALMEIDA, Paulo de | dep. fed. RJ | m | 1991 | 1995 |
| 520 | BASTOS, Laerte | dep. fed. RJ | m | 1991 | 1995 |
| 745 | MELO, Euclides de | dep. fed. SP | m | 1991 | 1995 |
| 923 | VIEIRA, Laprovita | dep. fed. RJ | m | 1991 | 1999 |
| ... | ... | ... | ... | ... | ... |
| 13587 | MENDES, João (2) | dep. fed. RJ | m | 1991 | 1993 |
| 14044 | JORGE, Eduardo | dep. fed. SP | m | 1991 | 1995 |
| 14082 | CAMPOS, Cidinha | dep. fed. RJ | f | 1991 | 1999 |
| 14674 | MARIANO, Maurici | dep. fed. SP | m | 1991 | 1995 |
| 14692 | MASCARENHAS, Eduardo | dep. fed. RJ | m | 1991 | 1993 |
66 rows × 5 columns
'dep. fed.' in "dep. fed. MT"
True
Exercícios#
Construa uma função para buscar apenas verbetes de personagens que tenham ocupado o cargo de deputado federal. Tabule os resultados incluindo o número de mandatos.
Construa uma função para buscar o primeiro verbete temático e apresente o seu conteúdo.
Encontre todos os verbetes que contenham “Academia Brasileira de Letras”. Que porcentagem destes correspondem a membros da dita academia?
Construa uma linha do tempo que represente a cobertura histórica do DHBB.
Exportando para Bancos de Dados#
Depois de realizarmos a nossa análise e tabular os resultados, podemos exportar a tabela em vários formatos. Em primeiro lugar, caso queiramos abri nossa trabalho em uma planilha, devemos salvar no formato CSV, ou “comma-separated-values”. Este formato pode ser aberto imediatamente em uma planilha.
tab.to_csv("minha_tabela.csv.gz", sep='|')
Acima usamos o caracter “|” como separador para evitar confusões com as virgulas existentes no texto.
Exportando para um banco de dados relacional#
Para exportar para um banco relacional, precisamos de uma biblioteca adicional, o SQLAlchemy. Estabiblioteca nos permite interagir com a maioria dos banco relacionais. Aqui vamos usar o banco SQLite.
from sqlalchemy import create_engine, text
engine = create_engine('sqlite:///minha_tabela.sqlite', echo=False)
tab.to_sql('resultados', con=engine, if_exists='replace')
7838
tab2.to_sql("cargos", con=engine, if_exists='replace')
15083
Uma vez inserido no banco relacional, podemos fazer consultas aos dados usando a linguagem SQL. Abaixo obtemos o resultado da consulta em uma lista.
with engine.connect() as con:
rs = con.execute(text("select * from resultados where natureza='temático'"))
print(rs.fetchall()[:10])
[(4, '6310.text', 'POLÍTICA DE CLIENTELA', 'temático', None, 'NA', '\n\nExpressão cunhada e conceito desenvolvido por Hélio Jaguaribe em seu\ntrabalho “Política ideológica e política de clientela”, publicado no\n«Jorn ... (2014 characters truncated) ... r derivação da expressão latina equivalente e das relações que, no\ninício da República Romana, existiam entre o pater famílias e seus\nclientes.\n\n'), (21, '5742.text', 'ASSEMBLÉIA NACIONAL CONSTITUINTE DE 1987-88', 'temático', None, 'NA', '\n\nNo dia 1º de fevereiro de 1987, os membros da Câmara dos Deputados e do\nSenado Federal reuniram-se, unicameralmente, em Assembléia Nacional\nCon ... (57523 characters truncated) ... nal ficou composto por 315 artigos, dos quais 245\ndistribuídos por oito títulos das disposições permanentes e 70 nas\ndisposições transitórias. \n\n'), (42, '5793.text', 'I CONGRESSO ANTIFASCISTA', 'temático', None, 'NA', '\n \nReunião realizada no Rio de Janeiro em agosto de 1934 sob a direção do\nPartido Comunista Brasileiro (PCB).\n\nSua finalidade era condenar a política fascista em ascensão. Contou,\nentre outras, com a presença de representantes operários.\n\n'), (52, '6346.text', 'REDE BANDEIRANTES', 'temático', None, 'NA', '\n\nRede de televisão pertencente ao grupo paulista Bandeirantes, fundado\npor João Jorge Saad, e que teve origem a partir da criação da TV\nBandeira ... (18363 characters truncated) ... ireção na emissora: Hélio Vargas (Direção de\nProgramação), Raimundo Lima (Direção de Produção) e Fernando Mitre\n(Direção Nacional de Jornalismo).\n'), (60, '11892.text', 'AGÊNCIA NACIONAL DE ENERGIA ELÉTRICA (ANEEL)', 'temático', None, 'NA', '\n\nAutarquia em regime especial, vinculada ao Ministério de Minas e Energia (MME), criada pela Lei nº 9.427, de 26 de dezembro de 1996, com a finali ... (39336 characters truncated) ... ão do aproveitamento hidrelétrico de Jirau, o segundo do Complexo do Rio Madeira, com capacidade estimada em 3.300 MW, foi realizado em maio de 2008.'), (66, '5703.text', 'AÇÃO CÍVICA NACIONAL', 'temático', None, 'NA', '\n\nPartido político do Rio de Janeiro (então Distrito Federal) fundado em\nmarço de 1933. Sua comissão central executiva era integrada por Luís\nMez ... (439 characters truncated) ... ão e a nacionalização da economia, e a defesa da\nreorganização política do país em bases novas, independente de quaisquer\ncoligações políticas.\n\n'), (67, '6221.text', 'PARTIDO REPUBLICANO REGENERADOR DO DISTRITO FEDERAL', 'temático', None, 'NA', '\n\nPartido político do Rio de Janeiro (então Distrito Federal) fundado em\n22 de setembro de 1934.\n\nSeu diretório central era constituído por Raul ... (872 characters truncated) ... rro Central do Brasil”.\n\nO partido pretendia eleger representantes à Câmara Municipal do Distrito\nFederal, mas não obteve êxito nesse sentido.\n\n'), (80, '5770.text', 'CÓDIGO DE MINAS', 'temático', None, 'NA', '\n\nO regime das minas no Brasil obedecia ao sistema estabelecido pelas\nOrdenações do Reino, pelo qual as minas eram de propriedade da Coroa.\nCom a ... (6078 characters truncated) ... 967)\nprocurou atualizar a legislação mineira no país, refletindo a\nexperiência de aplicação dos novos princípios legais pelo prazo de 33\nanos.\n\n'), (82, '5846.text', 'ELETROBRAS (Centrais Elétricas Brasileiras S.A.)', 'temático', None, 'NA', "\n\nEmpresa estatal criada em 25 de abril de 1961 pela Lei nº 3.890-A e\ninstalada em 11 de junho de 1962.\n\n## Antecedentes\n\nO desenvolvimento da ... (103944 characters truncated) ... 2009, a União detinha 52% das ações ordinárias com direito a voto,\ncorrespondentes a 41,5% do seu capital social, estimado em R$26.156\nmilhões.\n\n"), (83, '7789.text', 'COMISSÃO MISTA BRASIL-ESTADOS UNIDOS', 'temático', None, 'NA', '\n\nGrupo de trabalho oficialmente instalado na órbita e no próprio prédio\ndo Ministério da Fazenda em 19 de julho de 1951. Tendo completado seus\ne ... (10617 characters truncated) ... da Comissão Mista, em dezembro de 1953, coube ao BNDE\no encargo de levar avante as negociações para execução dos projetos por\nela recomendados.\n\n')]
Se quisermos os resultado na forma de um Dataframe, podemos usar o Pandas.
pd.read_sql_query("select * from resultados where natureza='temático'", con=engine).head()
| index | arquivo | title | natureza | sexo | cargos | corpo | |
|---|---|---|---|---|---|---|---|
| 0 | 4 | 6310.text | POLÍTICA DE CLIENTELA | temático | None | NA | \n\nExpressão cunhada e conceito desenvolvido ... |
| 1 | 21 | 5742.text | ASSEMBLÉIA NACIONAL CONSTITUINTE DE 1987-88 | temático | None | NA | \n\nNo dia 1º de fevereiro de 1987, os membros... |
| 2 | 42 | 5793.text | I CONGRESSO ANTIFASCISTA | temático | None | NA | \n \nReunião realizada no Rio de Janeiro em ag... |
| 3 | 52 | 6346.text | REDE BANDEIRANTES | temático | None | NA | \n\nRede de televisão pertencente ao grupo pau... |
| 4 | 60 | 11892.text | AGÊNCIA NACIONAL DE ENERGIA ELÉTRICA (ANEEL) | temático | None | NA | \n\nAutarquia em regime especial, vinculada ao... |